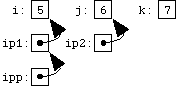
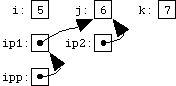
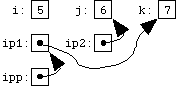
Since text strings are represented in C by arrays of characters, and since arrays are very often manipulated via pointers, character pointers are probably the most common pointers in C.
Deep sentence:
C does not provide any operators for processing an entire string of characters as a unit.We've said this sort of thing before, and it's a general statement which is true of all arrays. Make sure you understand that in the lines
char *pmessage; pmessage = "now is the time"; pmessage = "hello, world";all we're doing is assigning two pointers, not copying two entire strings.
At the bottom of the page is a very important picture. We've said that pointers and arrays are different, and here's another illustration. Make sure you appreciate the significance of this picture: it's probably the most basic illustration of how arrays and pointers are implemented in C.
We also need to understand the two different ways that string literals like "now is the time" are used in C. In the definition
char amessage[] = "now is the time";the string literal is used as the initializer for the array amessage. amessage is here an array of 16 characters, which we may later overwrite with other characters if we wish. The string literal merely sets the initial contents of the array. In the definition
char *pmessage = "now is the time";on the other hand, the string literal is used to create a little block of characters somewhere in memory which the pointer pmessage is initialized to point to. We may reassign pmessage to point somewhere else, but as long as it points to the string literal, we can't modify the characters it points to.
As an example of what we can and can't do, given the lines
char amessage[] = "now is the time"; char *pmessage = "now is the time";we could say
amessage[0] = 'N';to make amessage say "Now is the time". But if we tried to do
pmessage[0] = 'N';(which, as you may recall, is equivalent to *pmessage = 'N'), it would not necessarily work; we're not allowed to modify that string. (One reason is that the compiler might have placed the ``little block of characters'' in read-only memory. Another reason is that if we had written
char *pmessage = "now is the time"; char *qmessage = "now is the time";the compiler might have used the same little block of memory to initialize both pointers, and we wouldn't want a change to one to alter the other.)
Deep sentence:
The first function is strcpy(s,t), which copies the string t to the string s. It would be nice just to say s=t but this copies the pointer, not the characters.This is a restatement of what we said above, and a reminder of why we'll need a function, strcpy, to copy whole strings.
page 105
Once again, these code fragments are being written in a rather compressed way. To make it easier to see what's going on, here are alternate versions of strcpy, which don't bury the assignment in the loop test. First we'll use array notation:
void strcpy(char s[], char t[])
{
int i;
for(i = 0; t[i] != '\0'; i++)
s[i] = t[i];
s[i] = '\0';
}
Note that we have to manually append the '\0' to s after the loop. Note that in doing so we depend upon i retaining its final value after the loop, but this is guaranteed in C, as we learned in Chapter 3.Here is a similar function, using pointer notation:
void strcpy(char *s, char *t)
{
while(*t != '\0')
*s++ = *t++;
*s = '\0';
}
Again, we have to manually append the '\0'. Yet another option might be to use a do/while loop.All of these versions of strcpy are quite similar to the copy function we saw on page 29 in section 1.9.
page 106
The version of strcpy at the top of this page is my least favorite example in the whole book. Yes, many experienced C programmers would write strcpy this way, and yes, you'll eventually need to be able to read and decipher code like this, but my own recommendation against this kind of cryptic code is strong enough that I'd rather not show this example yet, if at all.
We need strcmp for about the same reason we need strcpy. Just as we cannot assign one string to another using =, we cannot compare two strings using ==. (If we try to use ==, all we'll compare is the two pointers. If the pointers are equal, they point to the same place, so they certainly point to the same string, but if we have two strings in two different parts of memory, pointers to them will always compare different even if the strings pointed to contain identical sequences of characters.)
Note that strcmp returns a positive number if s is greater than t, a negative number if s is less than t, and zero if s compares equal to t. ``Greater than'' and ``less than'' are interpreted based on the relative values of the characters in the machine's character set. This means that 'a' < 'b', but (in the ASCII character set, at least) it also means that 'B' < 'a'. (In other words, capital letters will sort before lower-case letters.) The positive or negative number which strcmp returns is, in this implementation at least, actually the difference between the values of the first two characters that differ.
Note that strcmp returns 0 when the strings are equal. Therefore, the condition
if(strcmp(a, b)) do something...doesn't do what you probably think it does. Remember that C considers zero to be ``false'' and nonzero to be ``true,'' so this code does something if the strings a and b are unequal. If you want to do something if two strings are equal, use code like
if(strcmp(a, b) == 0) do something...(There's nothing fancy going on here: strcmp returns 0 when the two strings are equal, so that's what we explicitly test for.)
To continue our ongoing discussion of which pointer manipulations are safe and which are risky or must be done with care, let's consider character pointers. As we've mentioned, one thing to beware of is that a pointer derived from a string literal, as in
char *pmessage = "now is the time";is usable but not writable (that is, the characters pointed to are not writable.) Another thing to be careful of is that any time you copy strings, using strcpy or some other method, you must be sure that the destination string is a writable array with enough space for the string you're writing. Remember, too, that the space you need is the number of characters in the string you're copying, plus one for the terminating '\0'.
For the above reasons, all three of these examples are incorrect:
char *p1 = "Hello, world!"; char *p2; strcpy(p2, p1); /* WRONG */
char *p = "Hello, world!"; char a[13]; strcpy(a, p); /* WRONG */
char *p3 = "Hello, world!"; char *p4 = "A string to overwrite"; strcpy(p4, p3); /* WRONG */In the first example, p2 doesn't point anywhere. In the second example, a is a writable array, but it doesn't have room for the terminating '\0'. In the third example, p4 points to memory which we're not allowed to overwrite. A correct example would be
char *p = "Hello, world!"; char a[14]; strcpy(a, p);(Another option would be to obtain some memory for the string copy, i.e. the destination for strcpy, using dynamic memory allocation, but we're not talking about that yet.)
page 106 continued (bottom)
Expressions like *p++ and *--p may seem cryptic at first sight, but they're actually analogous to array subscript expressions like a[i++] and a[--i], some of which we were using back on page 47 in section 2.8.
http://www.eskimo.com/~scs/cclass/krnotes/sx8e.html